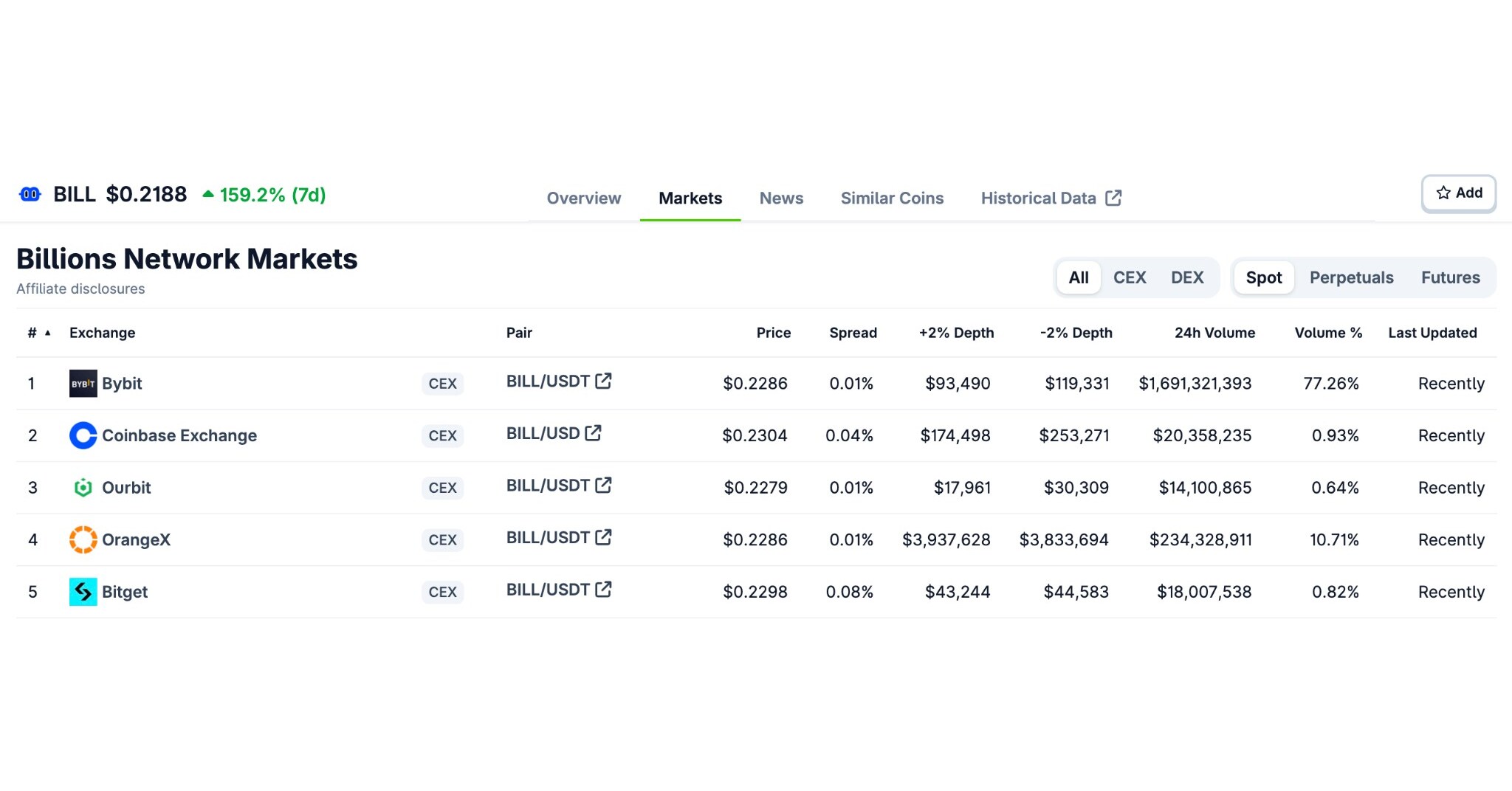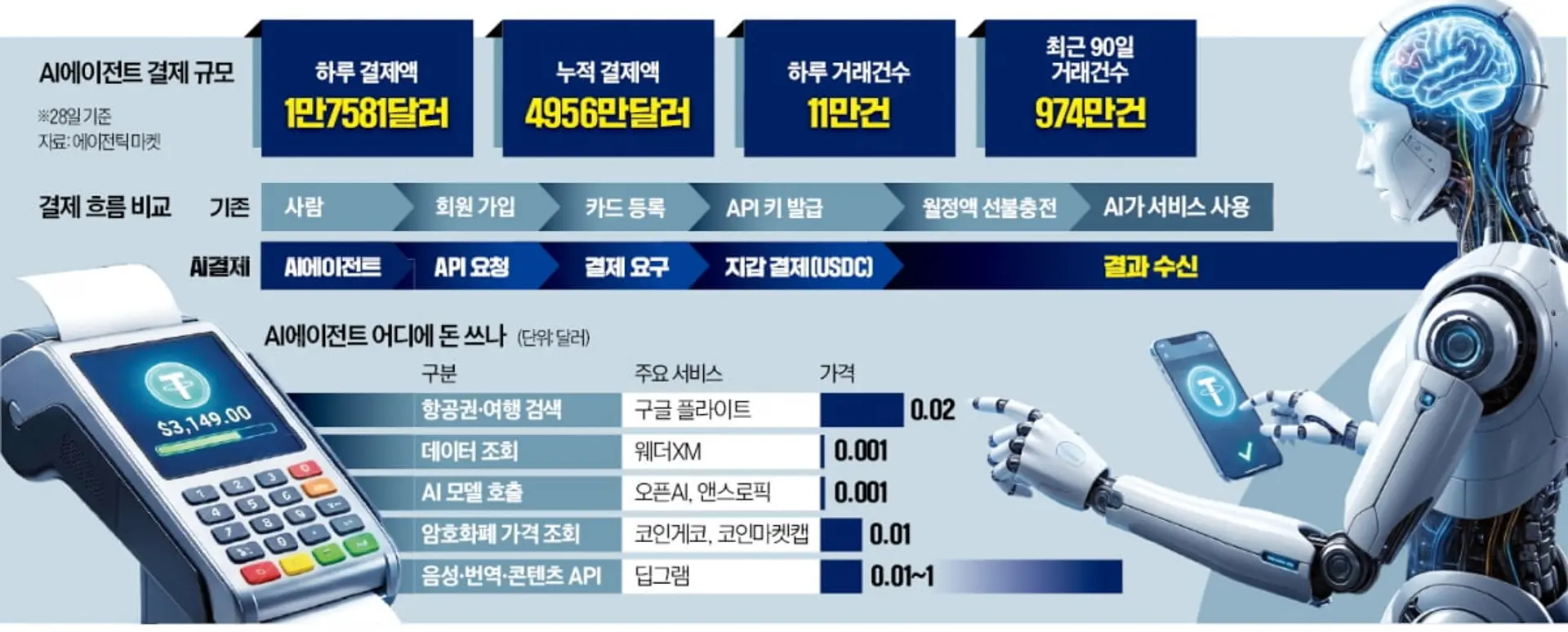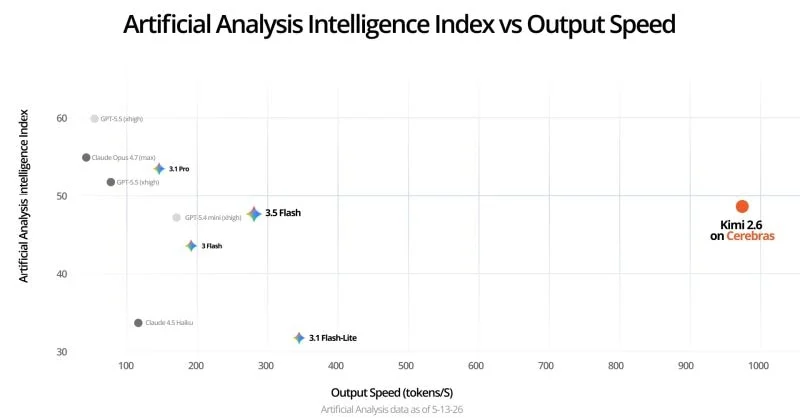
Cerebras Systems is now serving Moonshot AI’s Kimi K2.6, a 1-trillion-parameter open-weight Mixture-of-Experts model, at 981 output tokens per second. That number, verified by independent testing from Artificial Analysis, represents 6.7 times the speed of the next-best GPU cloud provider.
For context, the median inference provider clocks in at roughly 23 times slower.
What the numbers actually look like in practice
On a representative agentic coding workload, with 10,000 input tokens and 500 output tokens, the Cerebras-powered setup delivered a complete response in 5.6 seconds.
The same task on the official Kimi endpoint took 163.7 seconds. That’s a 29x improvement in end-to-end latency.
The Kimi K2.6 model itself is worth understanding. Developed by Moonshot AI and released on April 20, 2026, it features multimodal and agentic capabilities. While the total parameter count reaches 1 trillion, only 32 billion parameters are activated at any given time, thanks to the MoE architecture.
Why wafer-scale architecture changes the math
Cerebras’s core technology is the Wafer-Scale Engine, a chip that is an entire silicon wafer. Traditional chips are cut from wafers into small individual dies. Cerebras skips the cutting part and uses the whole thing.
Cerebras claims over 200 times the bandwidth of NVIDIA’s NVLink, the interconnect technology that links GPUs together in data center clusters. When running inference on large models, the bottleneck is almost always memory bandwidth, not raw compute. Weights need to be read from memory and fed to processors for every single token generated.
The business context: a freshly public company with something to prove
Cerebras completed its IPO in May 2026 at a valuation of $95 billion, making it the largest tech IPO of the year.
The 981 tokens-per-second result is the most concrete evidence yet that the speed half of that thesis holds up. Cerebras hasn’t published detailed pricing comparisons alongside this benchmark.
By serving one of the most prominent open-weight models from a leading Chinese AI lab, Cerebras is demonstrating that its hardware can handle the models that developers actually want to use.