Magesh Kasthuri
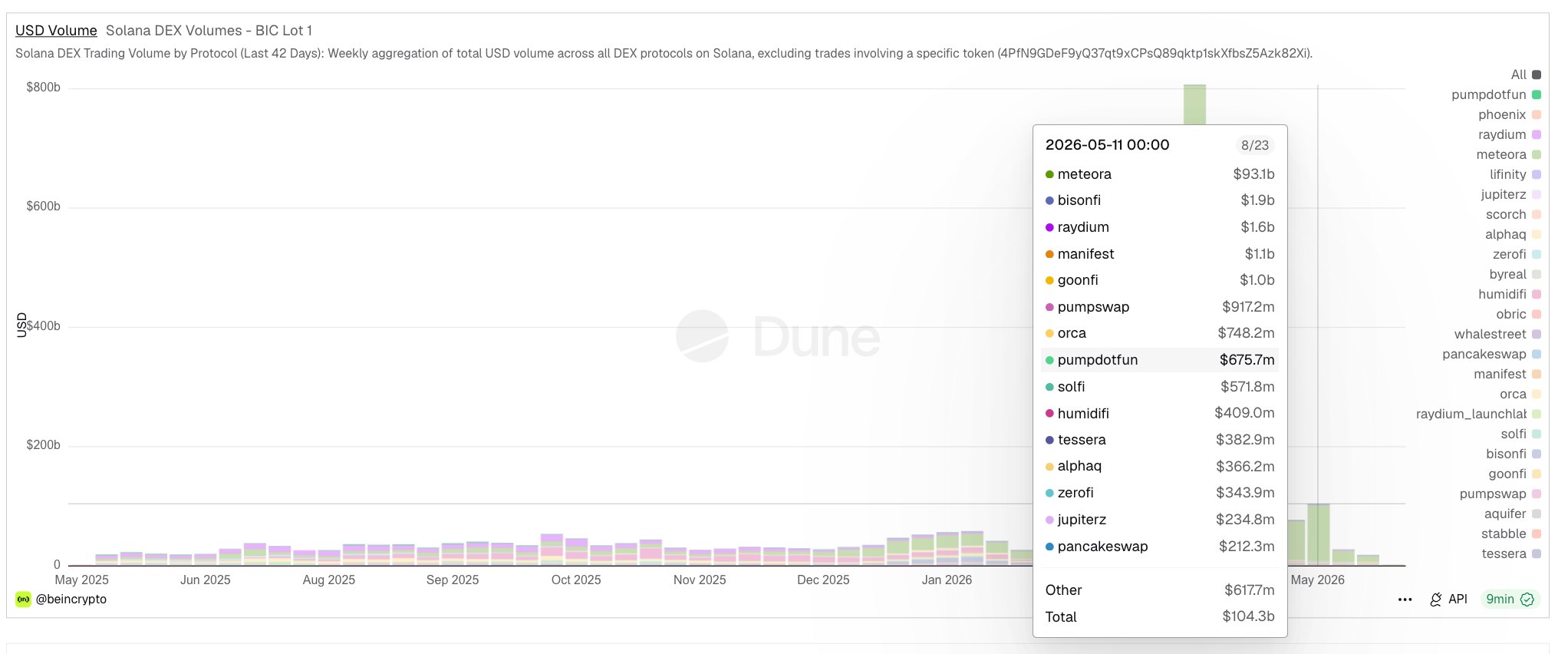
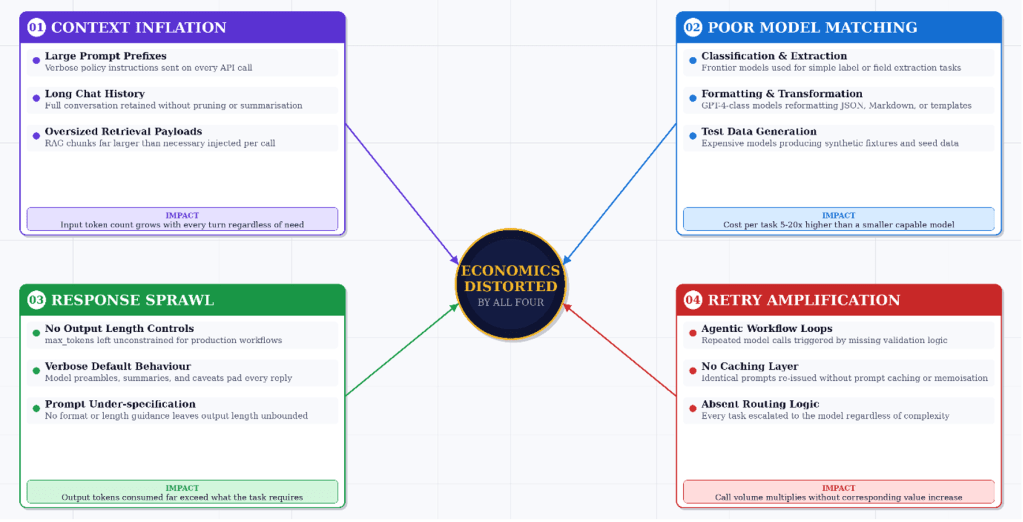
In practice, token costs are shaped by a handful of recurring patterns as per the Gartner report. The first is context inflation, where applications keep sending large prompt prefixes, verbose policy instructions, long chat history and oversized retrieval payloads on every call. The second is poor model matching, where high-end models are used for routine tasks such as classification, extraction, formatting or test data generation, even though smaller and cheaper models would do the job well. The third is response sprawl, where no output length controls are enforced and the model returns far more text than the user or process actually needs. The fourth is retry amplification, where agentic or automated workflows invoke the model repeatedly because the surrounding application lacks validation, caching or routing logic. Once AI usage expands across departments, these issues accumulate rapidly and can distort the economics of a program even when the underlying models are technically sound.
How an organization should plan token optimization
Organizations that manage AI well do not begin with model selection alone. They begin with operating intent. That means clearly identifying which use cases need premium reasoning, which use cases can tolerate lower latency or asynchronous processing, which ones need strict output controls and which ones are suitable for summarization or retrieval before generation. You can refer to Gartner’s “Tokenomics will become a new discipline” for guidelines.
A sensible token optimization plan usually starts with workload segmentation. Interactive experiences such as executive copilots, complex engineering assistance or contract analysis may justify higher-quality models. Routine workloads such as log classification, regression test explanation, boilerplate documentation, FAQ answering and metadata tagging often do not. Segmenting workloads this way allows the enterprise to create a service catalog for AI usage rather than exposing every consumer to the most expensive model by default.
The next step is governance. Every enterprise AI platform should collect token telemetry at the request level and aggregate it by application, environment, team, model and use case. Without that visibility, optimization becomes guesswork. Leaders should define token budgets, monthly thresholds, rate limits and environment-specific quotas. It is also wise to introduce approval paths for long-context models, tool-heavy agents and experimental multi-step reasoning workflows because these patterns can multiply token consumption very quickly.