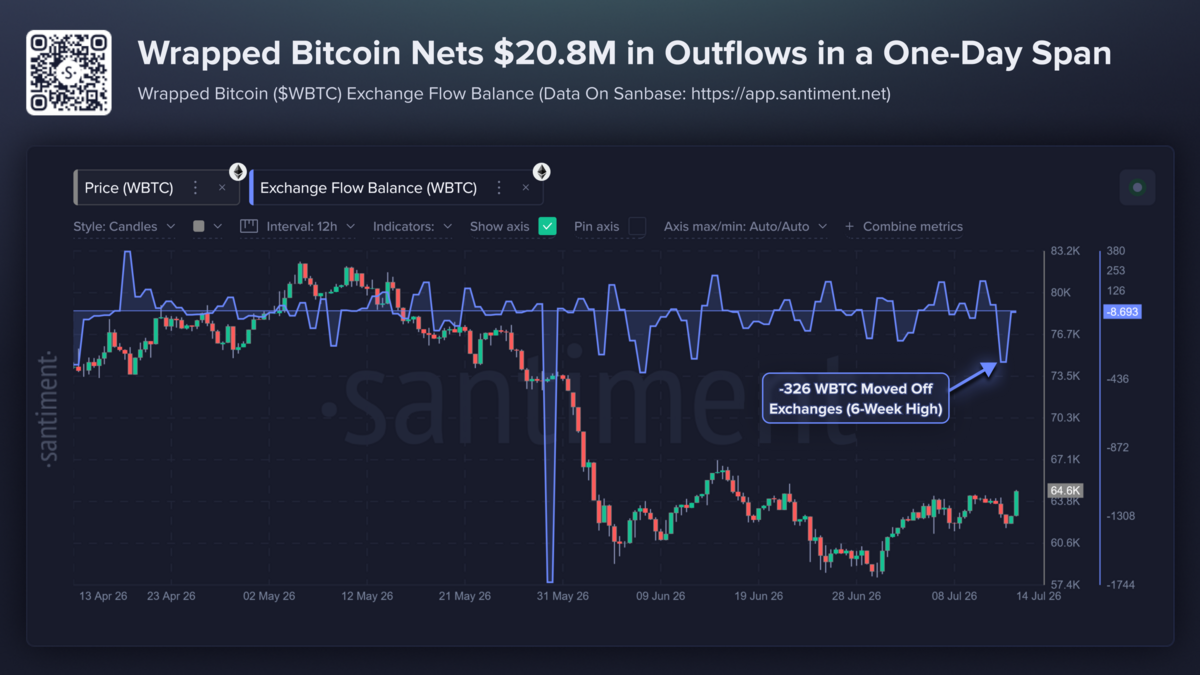
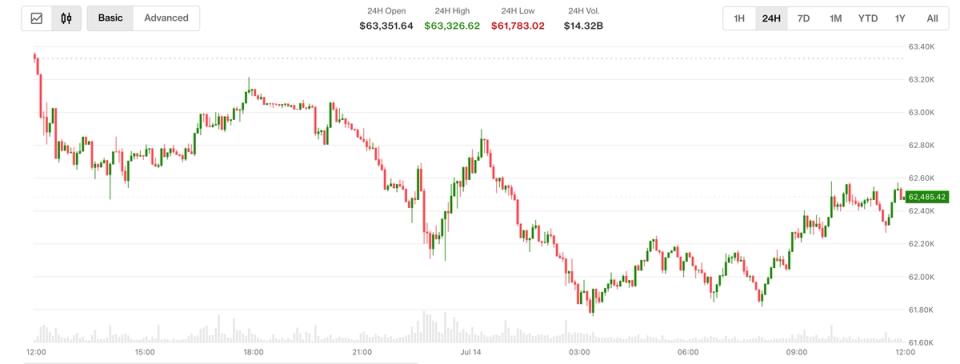
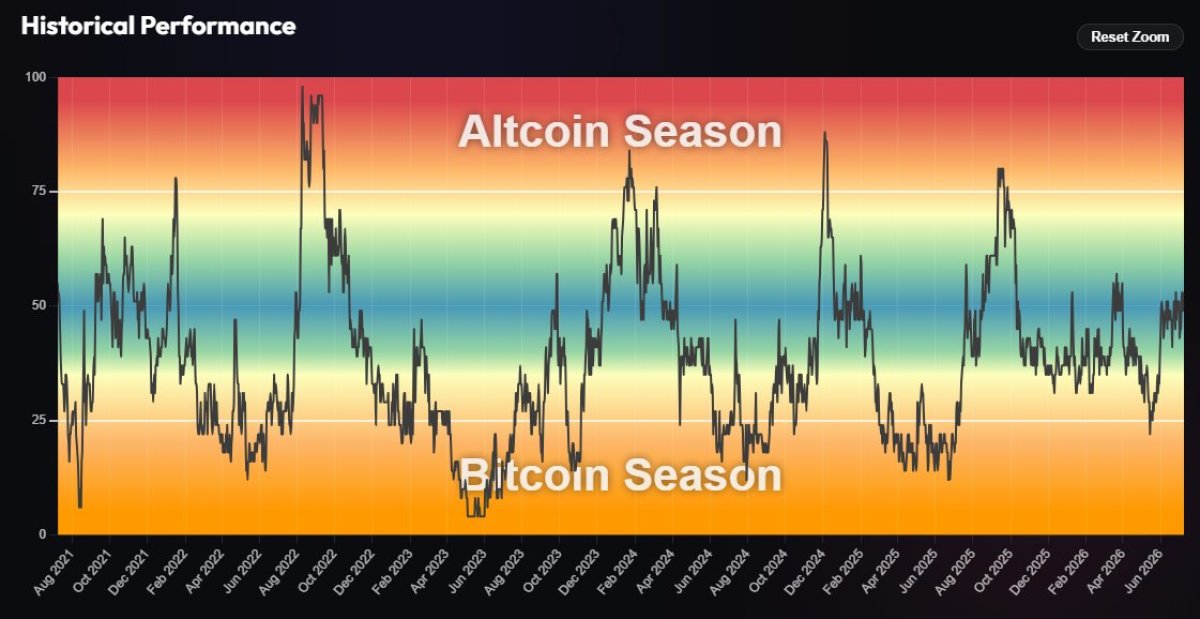
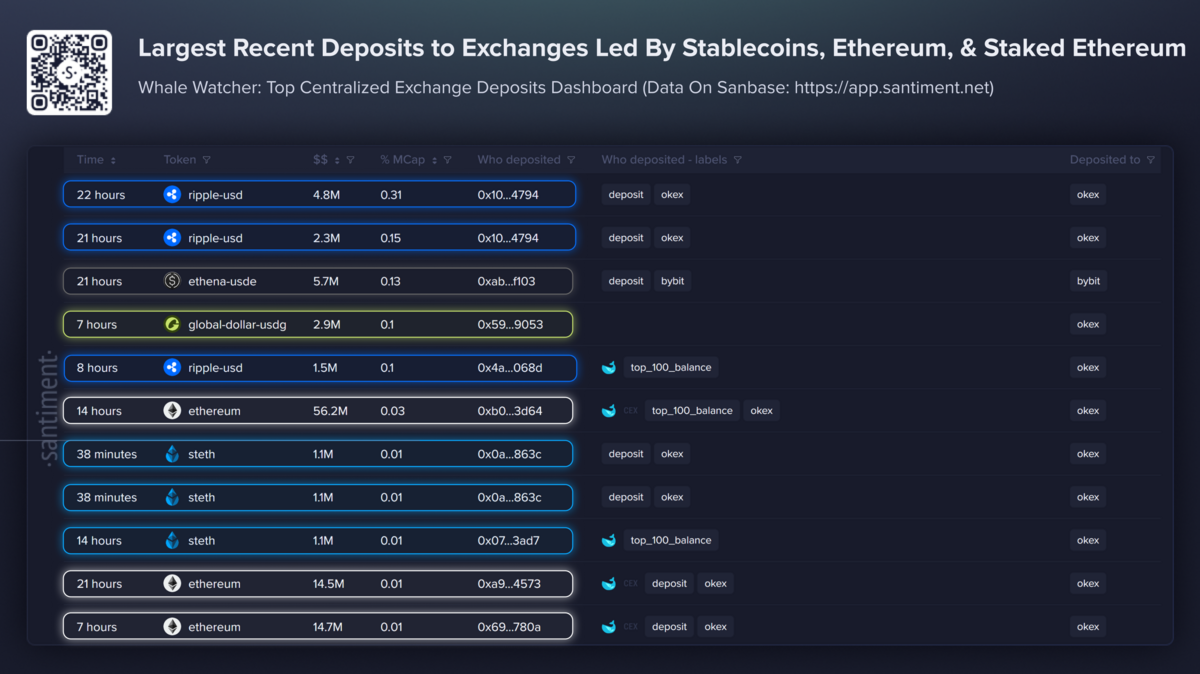
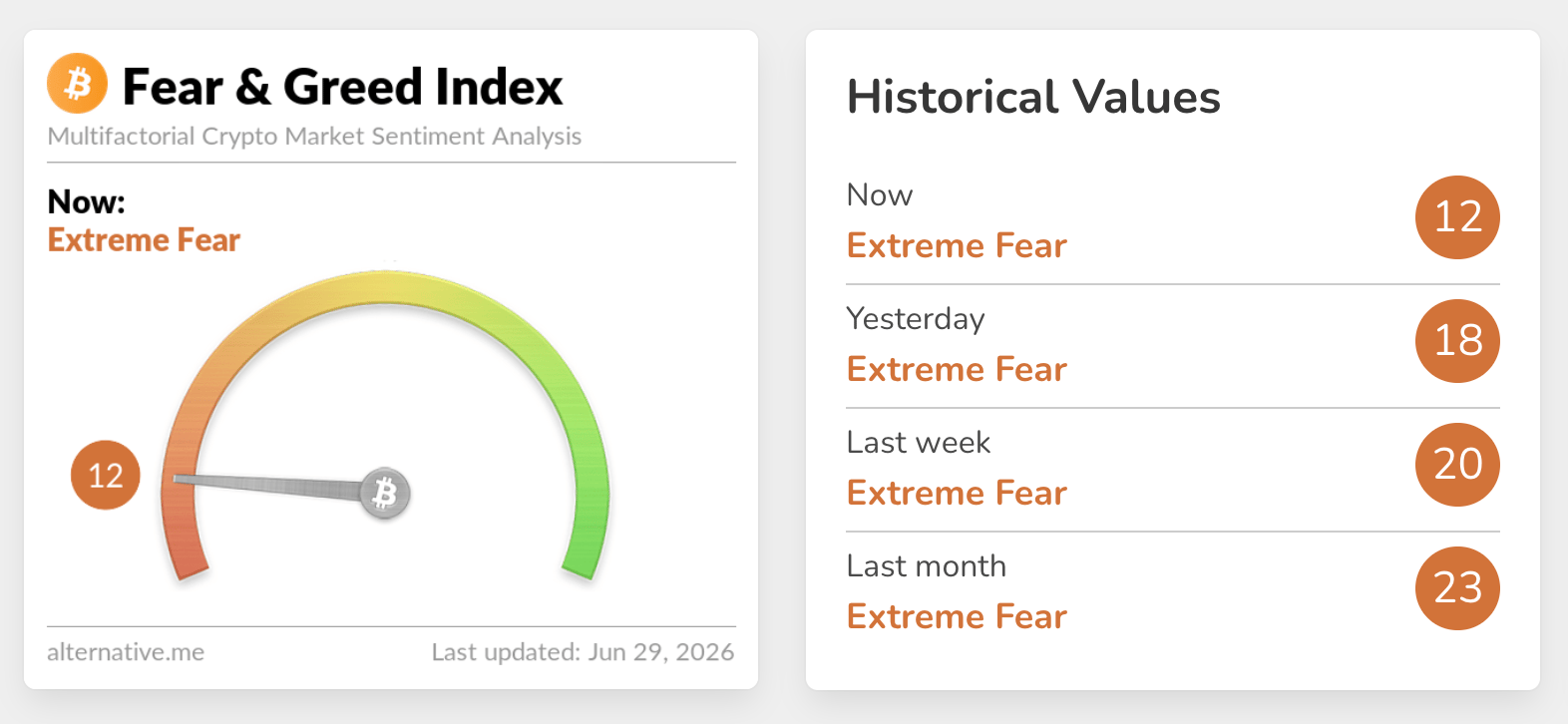
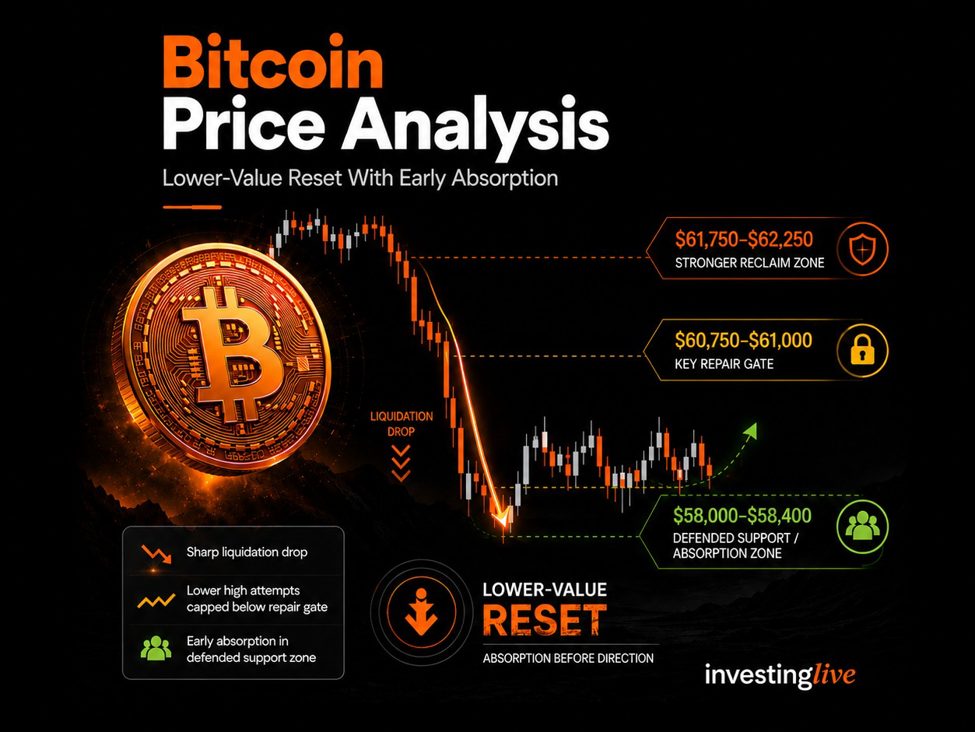
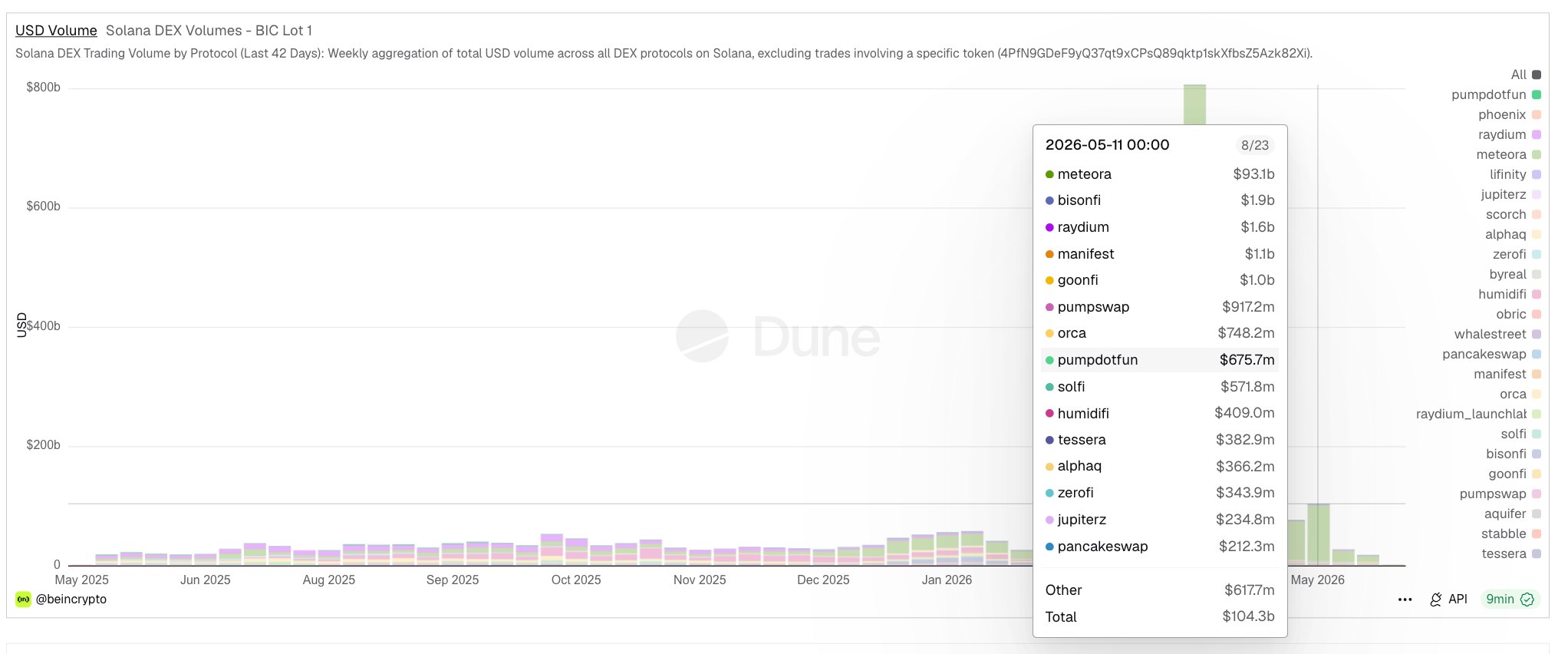
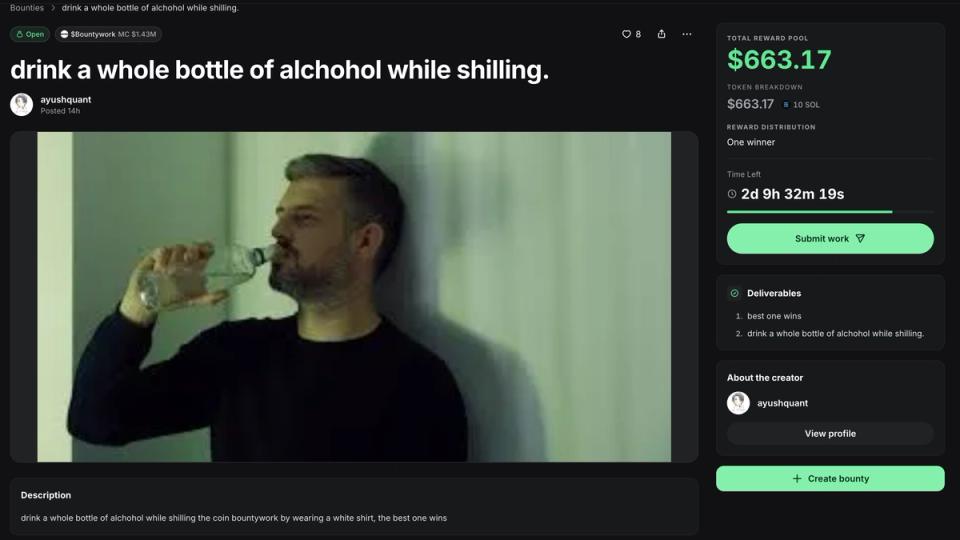
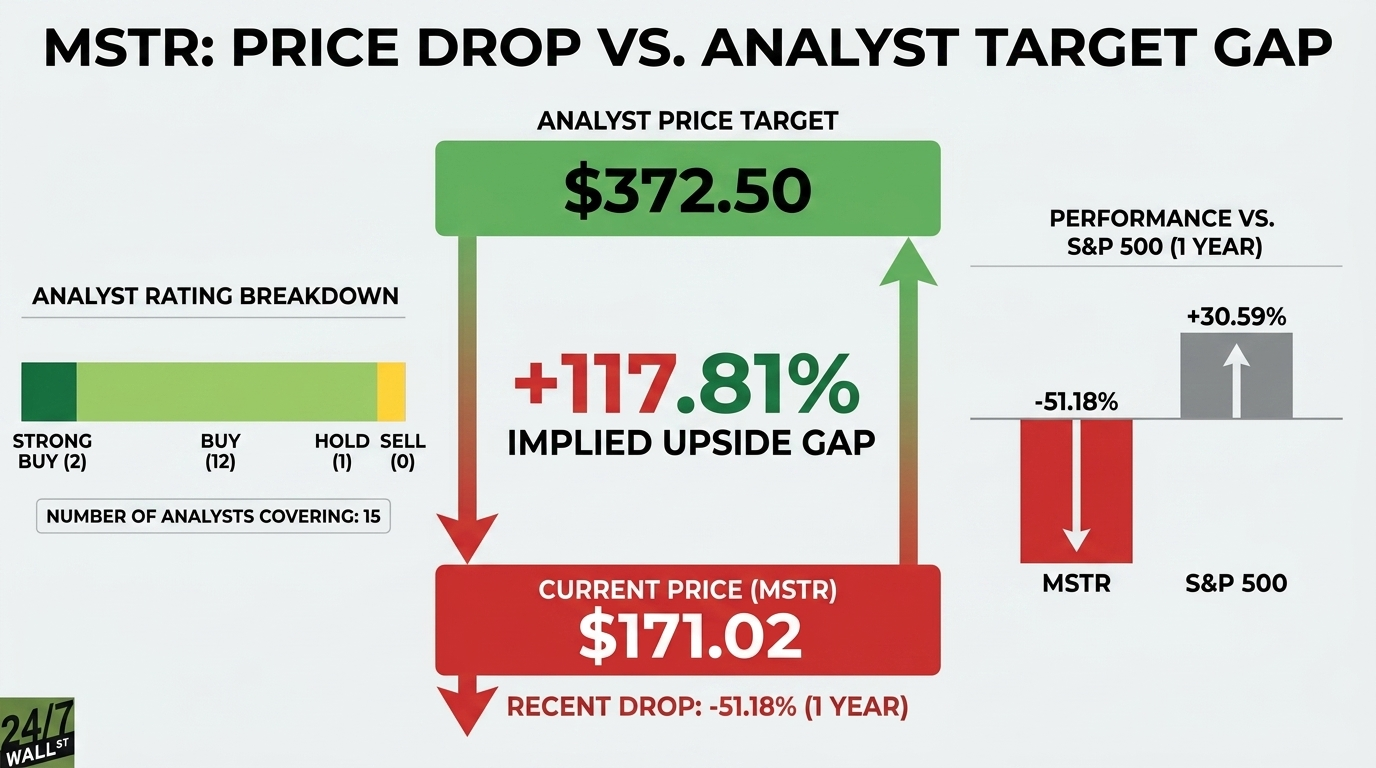
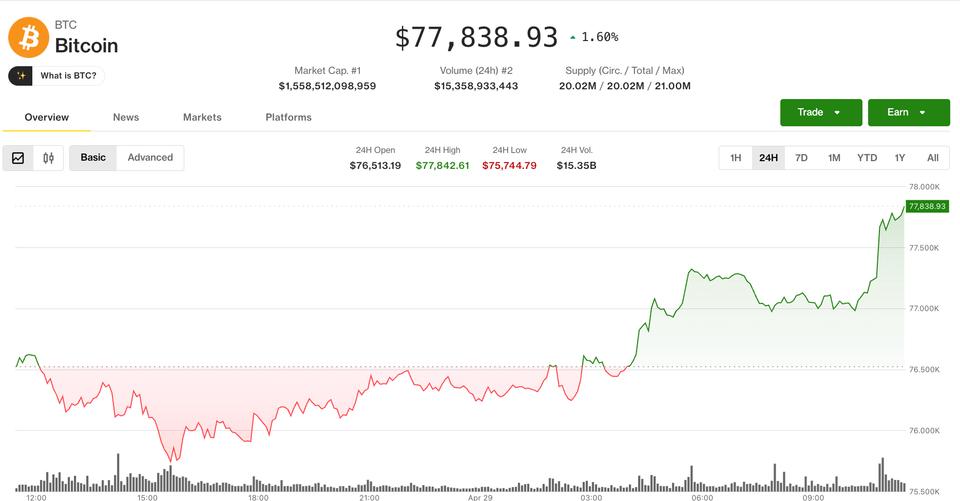
Multiple outlets report that Google unveiled Gemini 3.5 Flash at Google I/O 2026 as a faster, lower-cost inference option for large-scale enterprise workloads. Business Insider reports that companies are “already blowing through their annual token budgets” and that Google positioned a lower-cost model mix as a way to limit spending. VentureBeat and Nikkei published figures and claims from Google-linked coverage saying Gemini 3.5 Flash could slash enterprise AI costs, with VentureBeat reporting potential savings of more than $1 billion annually for some customers. Third-party pricing guides and blog summaries list per-1M-token examples and note Gemini 3.5 Flash is priced to compete on token efficiency versus other frontier models.