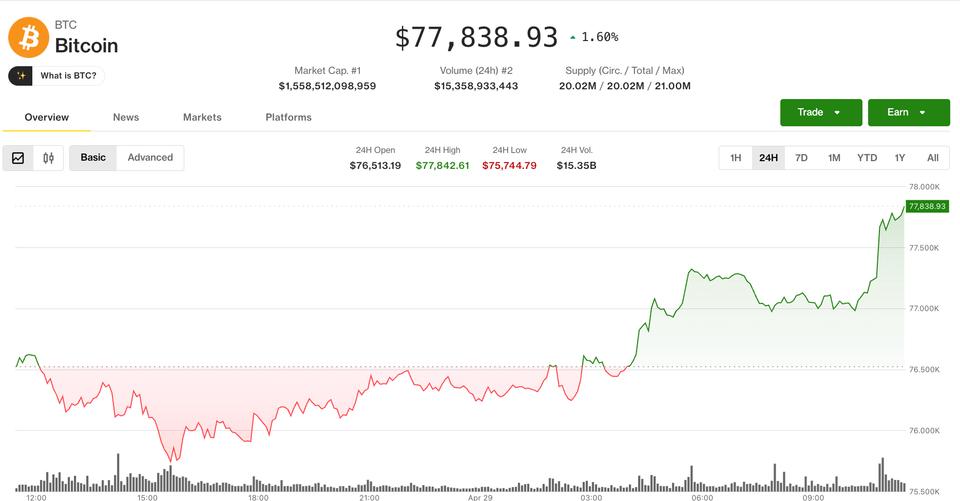
LAS VEGAS – Tokens were a hot topic at this week’s Cisco Live 2026 event, with company executives repeatedly pointing to the growing importance of “tokenomics” when it comes to managing AI usage.
“The way that we think about tokenomics is at every layer of the stack, you should be assessing what the metrics are for that layer,” Cisco chief product officer Jeetu Patel said during the Cisco Live event. “For example, the GPU layer. What’s your utilization look like on the infrastructure layer with GPUs, with memory, with network?”
There is then a need to go up to the model layer to check on performance, before then heading to the application layer to “make sure that the infrastructure is running at a steady pace and those applications are conducting tasks the way that they need them to,” Patel noted.
This then leads to the agent layer, which Patel said, “is the hardest, the behavior assessment of agents,” a task the executive noted was one reason for its recent acquisition of Galileo.
“We’ve actually built models now with Galileo that can assess behavior being out of the bounds of what would be deemed normal and then can make sure that we can intercept that behavior in certain ways,” Patel explained.
Cisco’s stack assessment is tied to getting a handle on token spend.
“People are really struggling with not knowing how much money they have to spend, and then finding themselves surprised because they’ve actually overspent money, and so this is an area where you can get full transparency, and over time even make sure that you can intercept, so that if the agent is going out of bounds and is actually consuming way too many tokens, you can intercept that agent and actually kill the agent if you needed to, so that you can make sure that that doesn’t actually blow your entire budget,” Patel added.
Token comfort level
This new tokenomics model is also part of a broader need for vendors and organizations to gain perspective on token use and demand going forward. Patel specifically noted the need to link token value with results.
“When you start thinking about where the risk lies, it would be when the cost of tokens and the value derived from the tokens actually have a distance, and that’s the thing that we, as an industry, have to be really careful of is you want to make sure that you’re economically generating tokens that create the necessary and desired output from an end-result perspective, on the core metrics that you, as a business, are trying to go out and measure, because that is going to be extremely important, that is in equilibrium with the cost of the tokens,” Patel explained. “If your costs go out of whack, but the benefit is not there, that’s when you will actually see some pullback.”
Patel added that this is why it’s important for an organization to get an early handle on their AI usage.
“I feel like across the board right now, the first phase that you get in AI is you have to get good with using it, which means you have to get familiar with it first. That consumes tokens,” Patel said of that initial stage. “Once you get familiar, then you get good and that’s when you start creating good outcomes. And once you get good, that’s when you start seeing very strong accretions of value with your company.”
The market overall is “still in phase one,” Patel noted. “Uniformly, all companies haven’t gotten good at this yet. We have to get good. Once you start getting good, you start seeing value and outputs get accreted in a very quantitative way.”
Wait, what are tokens?
For those out of the token loop, Deloitte’s Nicholas Merizzi provided an overview for SDxCentral late last year. In it, Merizzi described tokens as representing “a small unit of data – for example, part of a word, image, audio clip, or video. During inference or model training, AI models break down inputs into these units – or tokens – and process them step by step. The number of tokens used in an activity is now the primary billing metric in most AI services. Organizations pay by the number of tokens their AI consumes – whether that’s in prompts, outputs, or intermediate reasoning steps.”
However, Merizzi also provided the “caveat” that “token-based AI pricing introduces unpredictability because costs vary with prompt length, complexity, usage, and more. Unlike with traditional cost models, this can make budgeting challenging, and it can complicate planning for AI initiatives.”
Merizzi added that while token costs have dropped substantially over the past several years from “dollars-per-thousand tokens now cost[ing] fractions of a dollar-per-million. That should mean savings, right?”
“Well, not exactly,” Merizzi continued. “This is where Jevons’ Paradox comes in. As the cost per token falls, organizations don’t necessarily spend less; they just consume more. Complex tasks that were once too expensive to justify are now within reach. Chain-of-thought reasoning, for example, enables models to generate more accurate and nuanced responses, but it can consume up to 100-times more tokens per inference than traditional reasoning tasks. This trend will continue, especially as AI becomes embedded in more workflows.”