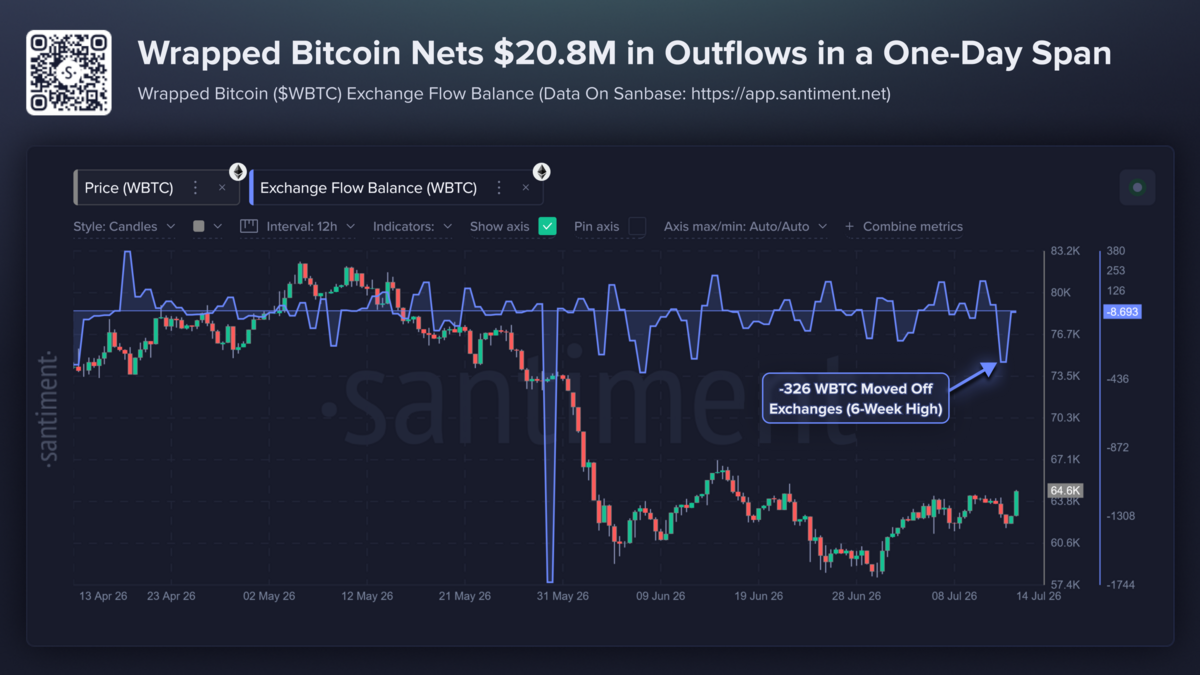
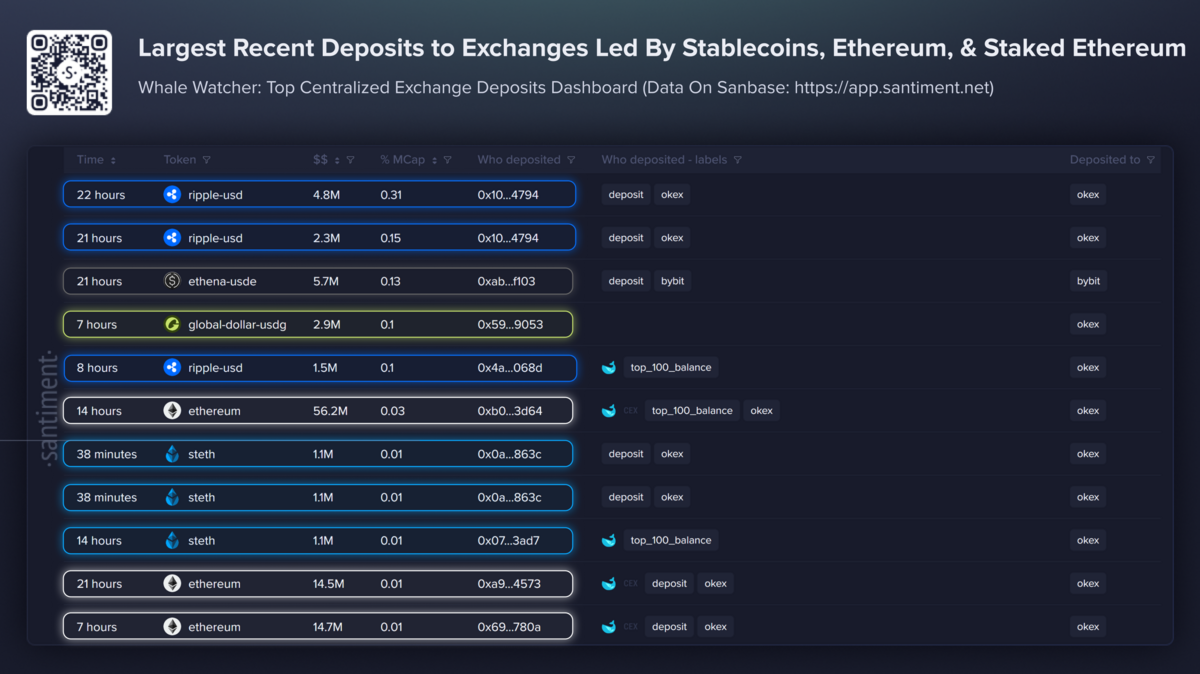
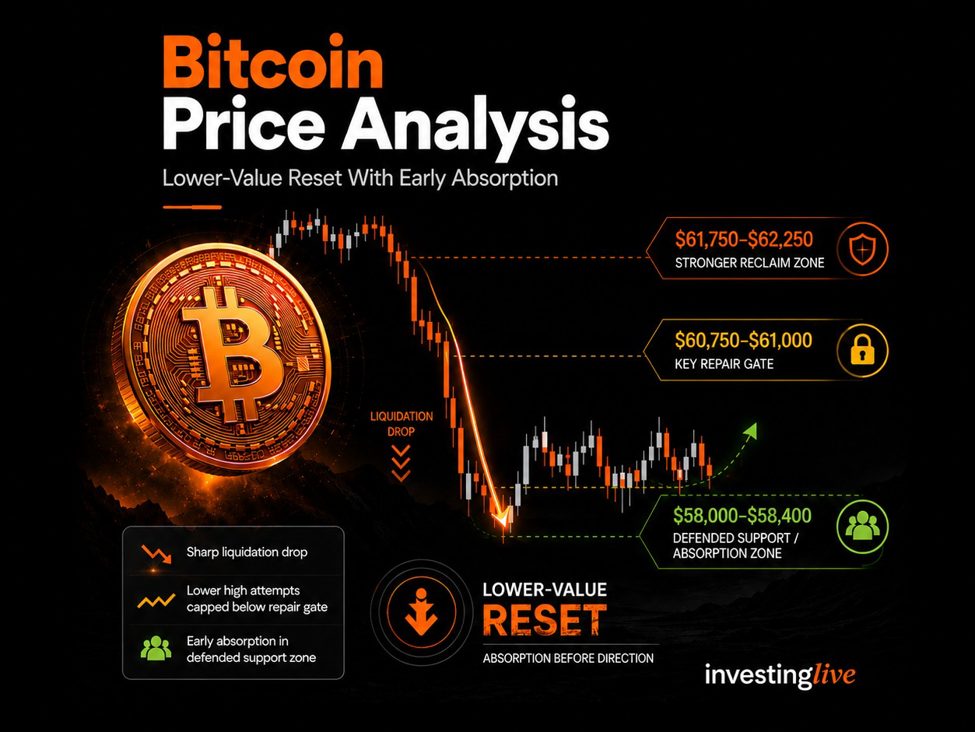
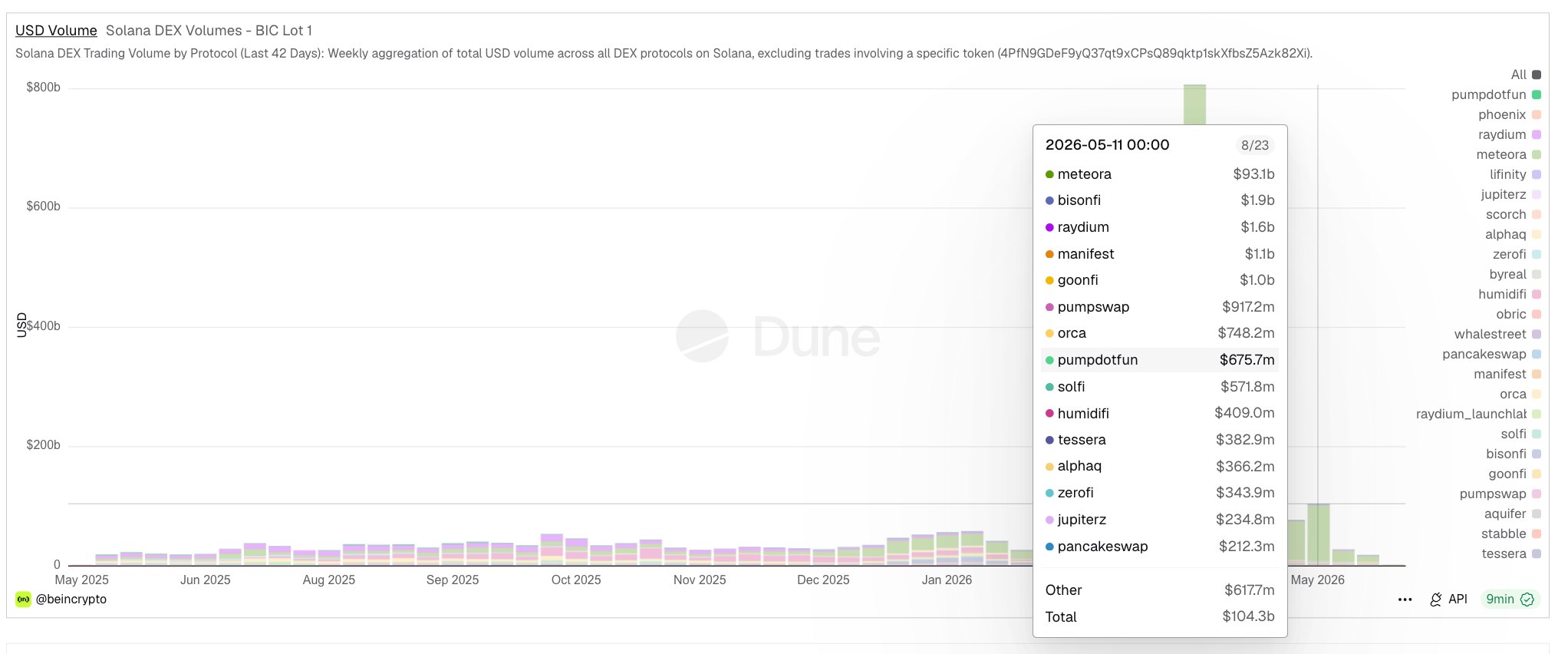
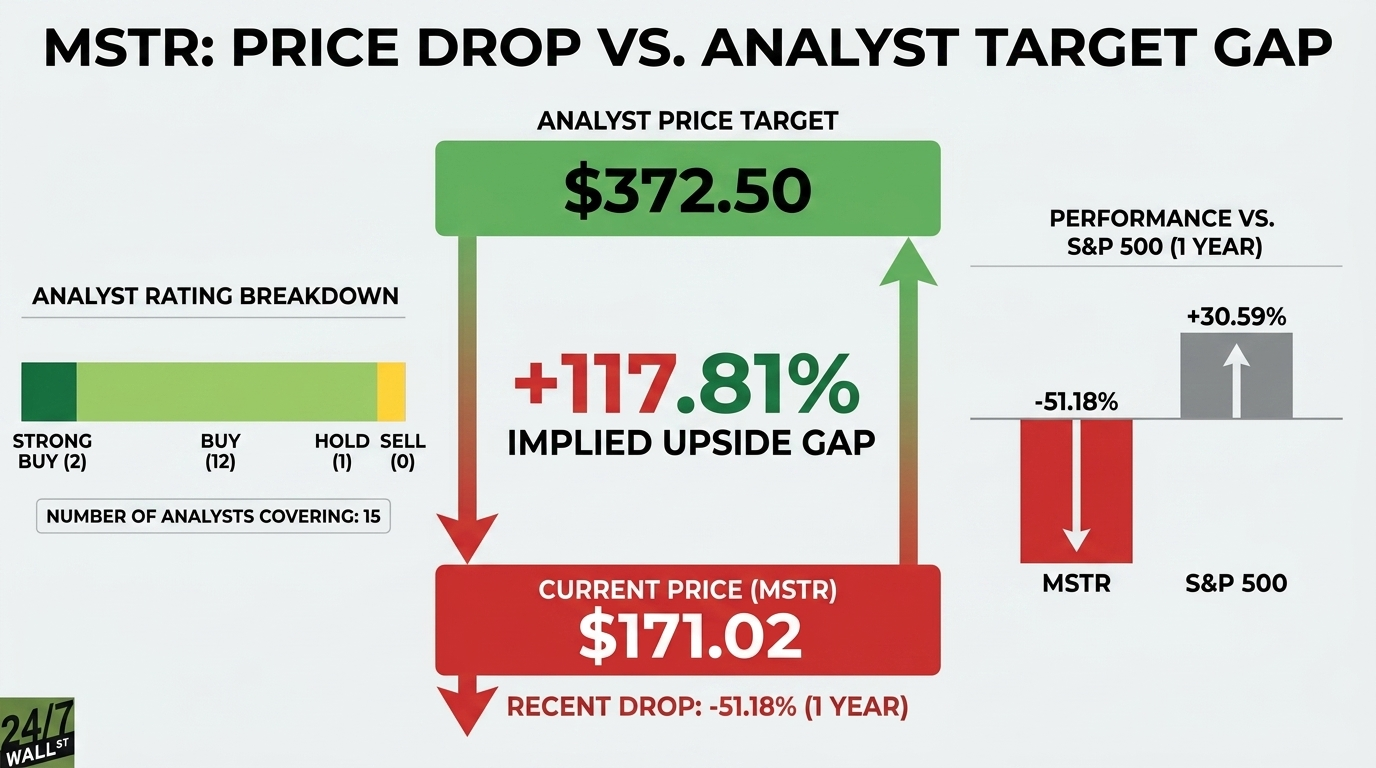
The Transformer did not merely become the dominant neural architecture. It became the default mental model for intelligence in modern AI.
Its central idea is deceptively simple: when processing a sequence, let every element look at every other element. A word can attend to previous words. A code token can attend to distant variables. An image patch can attend to another patch. A tool call can attend to an instruction buried thousands of tokens earlier. Attention turns sequence modeling into a giant differentiable lookup table over context.
This was a profound break from the recurrent era. Earlier models processed sequences like a reader moving left to right, updating a hidden state at each step. Transformers flattened that temporal process into a massively parallel computation. Instead of compressing the past into a single state, they exposed the entire past to the model. That made training easier, scaling more predictable, and long-range relationships easier to represent.
But every architecture has a physics. Transformers have the physics of global interaction. That physics is powerful, but expensive.
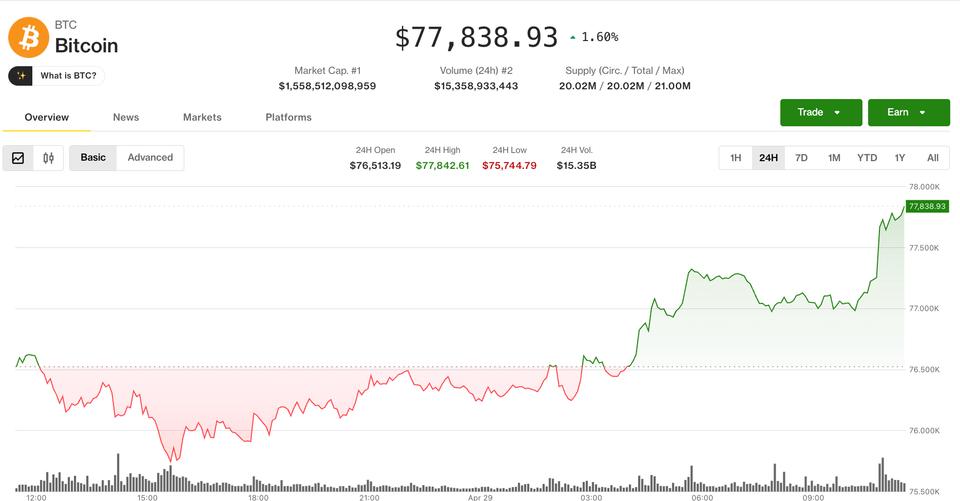
Self-attention wants to compare tokens against other tokens. During inference, the model accumulates a key-value cache so that each new token can attend to the past. As context grows, memory grows. As model size grows, serving complexity grows. As agents become longer-running, more tool-using, and more local, the cost of remembering everything explicitly becomes harder to ignore.
The Transformer is a brilliant architecture for cloud-scale intelligence. It is less obviously the final architecture for always-on, low-latency, private, embodied, on-device intelligence.
That is where liquid models enter the story.