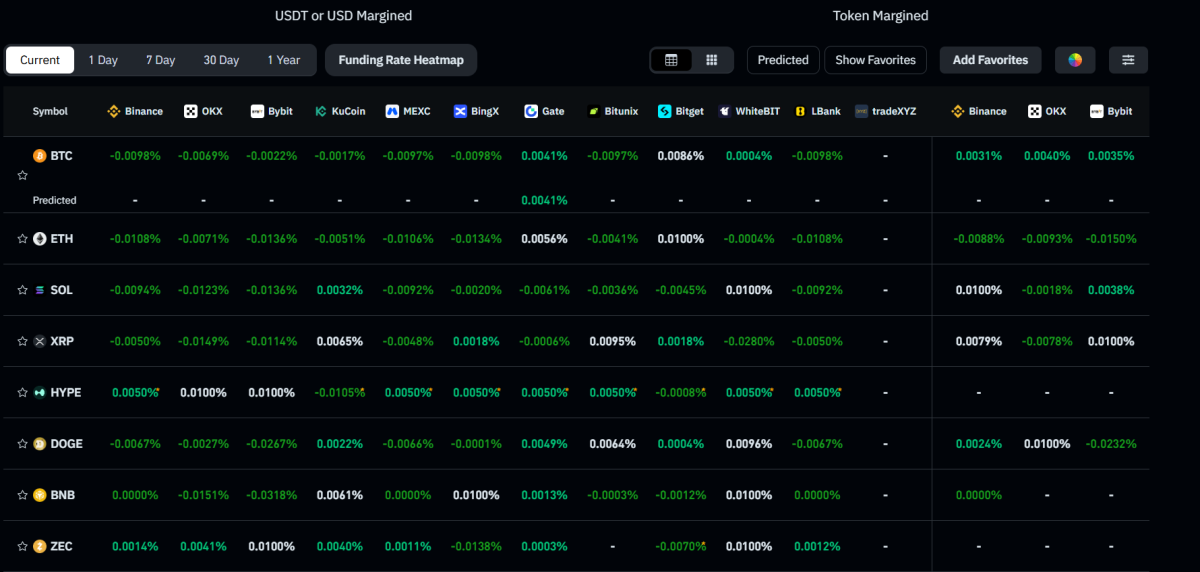
Google DeepMind released DiffusionGemma on June 10, 2026, an experimental open-weights model that writes text using discrete diffusion rather than the token-by-token method behind GPT-style systems, MarkTechPost reported. Google says it generates more than 1,000 tokens per second on a single Nvidia H100, up to four times faster than comparable autoregressive models, and ships it free under an Apache 2.0 license. For developers and anyone running AI locally, the news is not another chatbot, it is a different way of producing text that trades some quality for a large jump in speed.
Why Speed Has Been The Stubborn Limit For Language Models
To see why this matters, start with how nearly every popular language model works. Autoregressive models, the family that includes GPT and standard Gemma, generate text one token at a time, and each new token must wait for the previous one because it is conditioned on everything written so far. That sequential dependency is the fundamental reason long responses feel slow: the model cannot run ahead of itself. Throwing more hardware at the problem helps only so much, because the bottleneck is the one-after-another structure, not raw compute.
How Diffusion Text Generation Works: Denoising 256 Tokens In Parallel
DiffusionGemma attacks that bottleneck by borrowing the idea behind image generators. Instead of writing left to right, it starts from a “canvas” of noise tokens and iteratively denoises blocks of 256 tokens in parallel until coherent text emerges, as the NVIDIA engineering blog explains. Each denoising step refines the whole block at once rather than appending a single word, so the model produces many tokens per forward pass instead of one.
The architecture supports that approach. DiffusionGemma is a 26-billion-parameter mixture-of-experts model with 3.8 billion active parameters, meaning only a fraction of the network fires for any given input, which keeps it efficient. Generating 256 tokens in parallel per forward pass is what lets it reach 1,000-plus tokens per second on a single H100. The engineering tradeoff is explicit and worth understanding: parallel block denoising sacrifices some of the precise, context-by-context conditioning that makes autoregressive models accurate, in exchange for throughput.
The Honest Tradeoff: Faster, But Not Smarter
Google is unusually candid about the cost. DiffusionGemma’s output quality is lower than standard Gemma 4 on benchmarks such as MMLU and coding tests, and the company positions it as experimental, aimed at speed-critical workflows rather than as a new quality leader. That framing should shape how readers think about it. For tasks where latency dominates, drafting, autocomplete, on-device assistants, real-time interfaces, four-times-faster generation is transformative even at slightly lower accuracy. For tasks where correctness is paramount, a coding agent that must get the logic right, the quality gap matters more than the speed.
What You Can Do With It Today
Unlike a closed product, DiffusionGemma is something developers can actually pick up now. It is released under a permissive Apache 2.0 license on Hugging Face, Kaggle, and Google Cloud’s Vertex AI Model Garden, with day-zero optimization for Nvidia RTX hardware so it can run on local GPUs rather than only in the cloud. Open weights plus local acceleration is the combination that lets independent developers experiment with diffusion-based text without a hyperscaler bill, which is how a new paradigm spreads beyond the lab.
Frequently Asked Questions
What makes DiffusionGemma different from ChatGPT or standard Gemma?
Most models, including ChatGPT and standard Gemma, generate text one token at a time. DiffusionGemma uses discrete diffusion, denoising blocks of 256 tokens in parallel, which is what makes it up to four times faster.
Is DiffusionGemma free to use?
Yes. It is released under a permissive Apache 2.0 license and is available on Hugging Face, Kaggle, and Google Cloud’s Vertex AI Model Garden, with optimization for running locally on Nvidia RTX GPUs.
Is DiffusionGemma better than other AI models?
Not in quality. Google reports lower scores than standard Gemma 4 on benchmarks like MMLU and coding tests and positions it as experimental for speed-critical workflows, trading some accuracy for much faster generation.